Материалы по тегу: gtc 2024
|
24.03.2024 [02:06], Сергей Карасёв
Micron показала модули памяти MCR DIMM DDR5-8800 ёмкостью 256 ГбайтКомпания Micron, по сообщению ресурса Tom's Hardware, продемонстрировала на конференции NVIDIA GTC 2024 модули оперативной памяти MCR DIMM ёмкостью 256 Гбайт для серверов следующего поколения, в том числе для систем, построенных на процессорах Intel Xeon Granite Rapids. Модули имеют увеличенную высоту, но Micron также намерена выпустить варианты стандартной высоты для серверов типоразмера 1U. Изделия соответствуют стандарту DDR5-8800. С каждой стороны модуля расположены по 40 чипов памяти. Заявленное энергопотребление изделия составляет 20 Вт, тогда как у RDIMM объёмом 128 Гбайт при использовании профиля DDR5-4800 оно равно 10 Вт. Новые изделия Micron позволяют оснащать серверы 3 Тбайт памяти при наличии 12 слотов ОЗУ и 6 Тбайт при наличии 24 слотов. 
Источник изображения: Micron MCR DIMM использует специальный буфер между DRAM и CPU, который позволяет двум физическим рангам функционировать так, как если бы они были двумя отдельными модулями памяти, работающими параллельно. Это позволяет извлекать из памяти вдвое больше данных за каждый такт, а также увеличить скорость обмена информацией с CPU. Таким образом, можно одновременно поднять и ёмкость, и производительность памяти. SK hynix также поддерживает MCR DIMM, а вот AMD и JEDEC готовят альтернативный стандарт MRDIMM, который тоже поддерживает создание высокоёмких модулей DDR5-8800. Впрочем, концептуально оба решения восходят к OMI/DDIMM от IBM и даже FB-DIMM.
22.03.2024 [15:44], Владимир Мироненко
Schneider Electric и NVIDIA разработают эталонные проекты инфраструктуры ЦОД для ИИ-нагрузокФранцузская корпорация Schneider Electric объявила о сотрудничестве с NVIDIA с целью оптимизации инфраструктуры ЦОД, что позволит добиться новых достижений в области искусственного интеллекта (ИИ) и технологий цифровых двойников. Используя опыт в области инфраструктуры ЦОД и передовые ИИ-технологии NVIDIA, Schneider Electric разработает первые в своём роде общедоступные эталонные проекты дата-центров, призванные переопределить стандарты развёртывания и эксплуатации ИИ в экосистемах ЦОД. Эти проекты будут адаптированы для кластеров ускорителей NVIDIA и предназначены для поддержки нагрузок инженерного моделирования, автоматизации электронного проектирования, автоматизированного проектирования лекарств и генеративного ИИ. Особое внимание будет уделено обеспечению системам распределения большой мощности, системам жидкостного охлаждения и средствам управления для обеспечения простого ввода в эксплуатацию и надёжной работы высокоплотных кластеров. Эталонные проекты предложат надёжную основу для внедрения аппаратных платформ NVIDIA в ЦОД, одновременно оптимизируя производительность, масштабируемость и общую устойчивость объектов. Эти же проекты можно будет использовать для развёртывания ИИ-серверов высокой плотности в существующих ЦОД. 
Изображение: Steve Johnson / Unsplash В рамках объявленного сотрудничества AVEVA, дочерняя компания Schneider Electric, подключит свою платформу цифровых двойников к NVIDIA Omniverse, создав единую среду для виртуального моделирования и совместной работы. Это позволит ускорить проектирование и развёртывание сложных систем, а также сократить время их вывода на рынок и затраты. «Технологии NVIDIA расширяют возможности AVEVA по созданию реалистичного и захватывающего опыта совместной работы, основанного на богатых данных и возможностях интеллектуального цифрового двойника AVEVA», — отметил глава AVEVA.
22.03.2024 [09:09], Алексей Степин
NVIDIA представила 800G-платформы Quantum-X800 и Spectrum-X800 для InfiniBand- и Ethernet-фабрик нового поколенияДополнением к только что представленным ИИ-ускорителям NVIDIA Blackwell станут новые сетевые 800G-платформы Quantum-X800 и Spectrum-X800, а также сетевые адаптеры ConnectX-8. Именно они позволят вывести масштабирование ИИ-кластеров на новый уровень и позволят «прокормить» гигантские массивы ускорителей в дата-центрах гиперскейлеров. Платформа NVIDIA Quantum-X800 ориентирована на наиболее производительные ИИ- и HPC-кластеры. Она использует новое поколение технологии InfiniBand, всё ещё обладающей рядом преимуществ в сравнении с Ethernet, и включает в себя обновлённые SHARP-движки. Технология SHARPv4 реализует «вычисления в сети» (In-Network Computing), что позволяет не только существенно разгрузить вычислительные узлы и серверы, но и обеспечить более высокую пропускную способность интерконнекта вкупе с более серьёзными возможностями его масштабирования. 
NVIDIA Q3400-RA 4U (справа) и SN5600. Источник изображений здесь и далее: NVIDIA Основой платформы Quantum-X800 стал 4U-коммутатор Q3400-RA, впервые в индустрии, как говорит компания, использующий 200G-блоки SerDes для каждой линии InfiniBand. Коммутатор располагает 144 портами 800G в 72 OSFP-модулях и выделенным портом для Unified Fabric Manager. Новинка имеет стандартное 19″ исполнение с воздушным охлаждением, но есть и вариант Q3400-LD с жидкостным охлаждением, предназначенный для 21″ OCP-стоек. В двухуровневом варианте fat tree коммутаторы позволят объединить 10 368 NIC.  Основным адаптером для новой платформы InfiniBand является ConnectX-8 SuperNIC с интерфейсом PCIe 6.0. Он является частью SHARPv4 и предлагается в однопортовом (OSFP224) и двухпортовом (QSFP112) вариантах и в нескольких форм-факторах, включая OCP 3.0. На платах также имеется разъём SocketDirect на 16 линий PCIe. Также компания представила компоненты NVIDIA LinkX: оптические трансиверы 2xDR4/2xFR4 и активные медные кабели (LACC).  Не забыла NVIDIA и про Ethernet: здесь вывести производительность сети на новый уровень должна платформа Spectrum-X800. Её основой служит новейший коммутатор SN5600 — это, по словам NVIDIA, первый в мире Ethernet-коммутатор класса 800GbE, специально разработанный для применения гиперскейлерами в крупных облачных ИИ-комплексах. Применяемая архитектура позволяет гарантировать каждому клиенту оптимальный и постоянный уровень производительности, а потоковая телеметрия позволит находить и ликвидировать возможные «бутылочные горлышки» в сети буквально на лету.  Общая пропускная способность SN5600 составляет 51,2 Тбит/с. Коммутатор располагает 64 портами 800GbE в формате OSFP. В нём используется ASIC пятого поколения на базе архитектуры Spectrum-4. В качестве основного адаптера предлагается SuperNIC на базе DPU BlueField-3 с двумя 400GbE-портами. 
Фото: Twitter/NVIDIANetworkng Spectrum-X800 сопровождает полноценный спектр инфраструктурных компонентов, включая кабели DAC и LACC. С оптическими трансиверами длина соединения 800GbE может достигать двух километров. Начиная со следующего года, решения на базе новых сетевых платформ NVIDIA будут доступны от широкого круга поставщиков оборудования, включая Aivres, DDN, Dell Technologies, Eviden, Hitachi Vantara, HPE, Lenovo, Supermicro и VAST Data.
21.03.2024 [23:54], Владимир Мироненко
В Google Cloud появятся ускорители NVIDIA Grace BlackwellGoogle Cloud и NVIDIA объявили о расширении партнёрства, в рамках которого новая ИИ-платформа NVIDIA Grace Blackwell и NVIDIA DGX Cloud на её основе появятся в Google Cloud Platform, а клиентам станут доступны инференс-микросервисы NVIDIA NIM. Также было сказано об общедоступности DGX Cloud на базе NVIDIA H100. 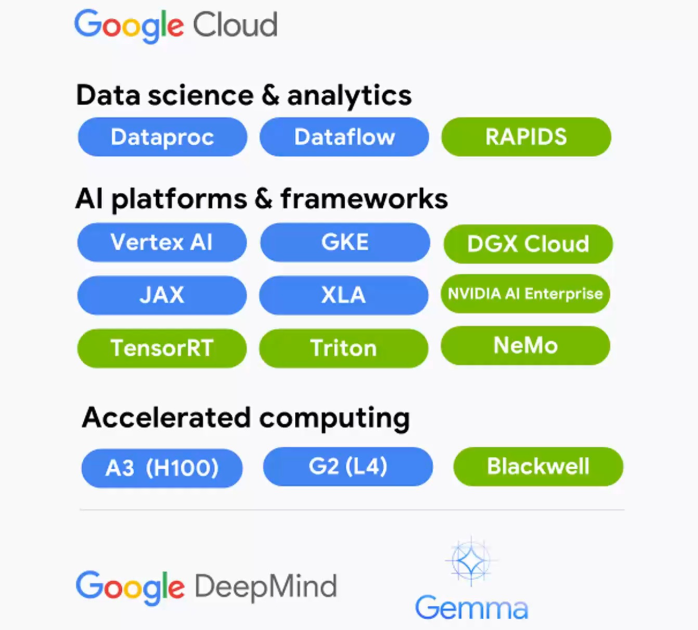
Источник изображения: NVIDIA Среди ключевых нововведений отмечены следующие:
21.03.2024 [22:21], Сергей Карасёв
Eviden создаст для Дании ИИ-суперкомпьютер Gefion на базе NVIDIA DGX SuperPOD H100Компания Eviden, дочерняя структура Atos, объявила о заключении соглашения с Датским центром инноваций в области искусственного интеллекта (Danish Centre for AI Innovation) на создание передового суперкомпьютера для решения ИИ-задач. Вычислительный комплекс под названием Gefion, как ожидается, заработает до конца текущего года. Как сообщается, в основу Gefion ляжет платформа NVIDIA DGX SuperPOD. Конфигурация включает 191 систему NVIDIA DGX H100, а общее количество ускорителей NVIDIA H100 составит 1528 штук. Говорится о применении интерконнекта NVIDIA Quantum-2 InfiniBand. В состав суперкомпьютера также войдут 382 процессора Intel Xeon Platinum 8480C поколения Sapphire Rapids. Эти чипы насчитывают 56 ядер (112 потоков), работающих на частоте 2,0/3,8 ГГц. Для подсистемы хранения выбрано решение DataDirect Networks (DDN). Ожидаемая ИИ-производительность Gefion на операциях FP8 составит около 6 Эфлопс. В рамках проекта Eviden отвечает за доставку компонентов комплекса, монтаж и пуско-наладочные работы. Система разместится в дата-центре Digital Realty. Её питание будет на 100 % обеспечиваться за счёт энергии из возобновляемых источников. 
Источник изображения: NVIDIA Датский центр инноваций в области ИИ принадлежит фонду Novo Nordisk Foundation и Экспортно-инвестиционному фонду Дании. При этом Novo Nordisk Foundation, основанный в Дании ещё в 1924 году, представляет собой корпоративный фонд с филантропическими целями. Его видение заключается в улучшении здоровья людей, повышении устойчивости общества и планеты. Отмечается, что Novo Nordisk Foundation обеспечит финансирование центра в размере примерно 600 млн датских крон (около $87,5 млн), а Экспортно-инвестиционный фонд — 100 млн датских крон ($14,6 млн).
21.03.2024 [00:51], Владимир Мироненко
Облачный ИИ-суперкомпьютер AWS Project Ceiba получит 21 тыс. суперчипов NVIDIA GB200
aws
b100
dgx cloud
gb200
gtc 2024
hardware
nvidia
ии
инференс
информационная безопасность
облако
суперкомпьютер
Amazon Web Services (AWS) и NVIDIA объявили о расширении сотрудничества, в рамках которого ускорители GB200 и B100 вскоре появятся в облаке AWS. Кроме того, компании объявили об интеграции Amazon SageMaker с NVIDIA NIM для предоставления клиентам более быстрого и дешёвого инференса, о появлении в AWS HealthOmics новых базовых моделей NVIDIA BioNeMo, а также о поддержке AWS обновлённой платформы NVIDIA AI Enterprise. Сотрудничество двух компаний позволило объединить в единую инфраструктуру их новейшие технологии, в том числе многоузловые системы на базе чипов NVIDIA Blackwell, ПО для ИИ, AWS Nitro, сервис управления ключами AWS Key Management Service (AWS KMS), сетевые адаптеры Elastic Fabric (EFA) и кластеры EC2 UltraCluster. Предложенная инфраструктура и инструменты позволят клиентам создавать и запускать LLM с несколькими триллионами параметров быстрее, в больших масштабах и с меньшими затратами, чем позволяли EC2-инстансы с ускорителями NVIDIA прошлого поколения. AWS предложит кластеры EC2 UltraClusters из суперускорителей GB200 NVL72, которые позволят объединить тысячи чипов GB200. GB200 будут доступны и в составе инстансов NVIDIA DGX Cloud. AWS также предложит EC2 UltraClusters с ускорителями B100. Amazon отмечает, что сочетание AWS Nitro и NVIDIA GB200 ещё больше повысит защиту ИИ-моделей: GB200 обеспечивает шифрование NVLink, EFA шифрует данные при передаче между узлами кластера, а KMS позволяет централизованно управлять ключами шифрования. 
Источник изображения: NVIDIA Аппаратный гипервизор AWS Nitro, как и прежде, разгружает CPU узлов, беря на себя обработку IO-операций, а также защищает код и данные во время работы с ними. Эта возможность, доступная только в сервисах AWS, была проверена и подтверждена NCC Group. Инстансы с GB200 поддерживают анклавы AWS Nitro Enclaves, что позволяет напрямую взаимодействовать с ускорителем и данными в изолированной и защищённой среде, доступа к которой нет даже у сотрудников Amazon. 
Источник изображения: NVIDIA Чипы Blackwell будут использоваться в обновлённом облачном суперкомпьютере AWS Project Ceiba, который будет использоваться NVIDIA для исследований и разработок в области LLM, генерация изображений/видео/3D, моделирования, цифровой биологии, робототехники, беспилотных авто, предсказания климата и т.д. Эта первая в своём роде машина на базе GB200 NVL72 будет состоять из 20 736 суперчипов GB200, причём каждый из них получит 800-Гбит/с EFA-подключение. Пиковая FP8-производительность системы составит 414 Эфлопс.
20.03.2024 [15:25], Руслан Авдеев
BNY Mellon стал первым транснациональным банком, внедрившим ИИ-суперкомпьютер NVIDIA на базе DGX SuperPOD H100Банк Bank of New York Mellon Corporation (BNY Mellon) стал первой структурой подобного профиля и масштаба, приступившей к внедрению собственного ИИ-суперкомпьютера на основе систем NVIDIA. Банку получил кластер DGX SuperPOD из нескольких десятков систем DGX H100, объединённых интерконнектом NVIDIA InfiniBand. Основанный в 2007 году в результате слияния The Bank of New York и Mellon Financial Corporation банк намерен использовать новый суперкомпьютер вкупе с NVIDIA AI Enterprise для создания и внедрения ИИ-приложений и управления ИИ-инфраструктурой своего бизнеса. Банк уже использует более 20 ИИ-решений, в том числе для прогнозирования в сфере депозитов, автоматизации платежей, предиктивной торговой аналитики и т.д. Всего же компания нашла более 600 вариантов использования ИИ в своей банковской системе. Как заявляют в руководстве BNY Mellon, внедрение ИИ-суперкомпьютера увеличит возможности по обработке данных и запуску ИИ-проектов, помогающих управлять активами клиентов и обеспечивать их защиту. 
Источник изображения: NVIDIA Компания пока не сообщила, где будет расположен суперкомпьютер и его полные характеристики. Ранее банку принадлежал дата-центр в Нью-Джерси, также он управлял IT-объектами в Пенсильвании и Теннесси.
20.03.2024 [02:17], Владимир Мироненко
Oracle и NVIDIA предложат суверенные ИИ-фабрики
dgx cloud
gb200
gtc 2024
nvidia
oracle
oracle cloud infrastructure
software
ии
конфиденциальность
облако
частное облако
Oracle и NVIDIA объявили о расширении сотрудничества для предоставления суверенного ИИ клиентам по всему миру — программно-аппаратные решения обеих компаний позволят правительствам и предприятиями формировать ИИ-фабрики, говорится в пресс-релизе. Облачные сервисы Oracle используют ряд платформ NVIDIA, включая аппаратную инфраструктуру и программную платформу NVIDIA AI Enterprise, в том числе недавно анонсированные микросервисы вывода NVIDIA NIM. Такие ИИ-фабрики позволят развернуть облачные сервисы, работающие локально и размещённые в безопасных кампусах на территории страны или организации. Сочетание полнофункциональной ИИ-платформы NVIDIA с корпоративным ИИ-инструментами Oracle, которые можно развернуть в выделенном регионе OCI, позволит получить современное ИИ-решение с повышенным уровенем контроля, защиты и безопасности. По словам Oracle, компания является единственным гиперскейлером, способным предоставлять ИИ-решения и полноценные облачные услуги локально и в любом месте. Oracle также задействует чипы NVIDIA Blackwell (GB200 и B200) в OCI Supercluster и OCI Compute. OCI Supercluster станет значительно быстрее благодаря новым bare metal-инстансам, RDMA-сети со сверхмалой задержкой и высокопроизводительному хранилищу. В OCI появятся и сервисы NVIDIA NIM и CUDA-X, а также NVIDIA NeMo Retriever. 
Источник изображения: NVIDIA Наконец, в DGX Cloud on OCI станут доступны инстансы на базе суперускорителей GB200 NVL72 для работы с LLM с триллионами параметров. Полный кластер DGX Cloud будет включать более 20 тыс. ускорителей GB200, интерконнект NVLink 5 и сеть NVIDIA InfiniBand XDR.
20.03.2024 [01:00], Владимир Мироненко
Microsoft и NVIDIA объявили об интеграции своих решений для ускорения внедрения генеративного ИИ на предприятияхMicrosoft и NVIDIA объявили о расширении давнего сотрудничество с целью внедрения новейших технологий генеративного ИИ NVIDIA и Omniverse в Microsoft Azure и ИИ-сервисы Azure, Microsoft Fabric и Microsoft 365. Сатья Наделла (Satya Nadella), председатель и гендиректор Microsoft заявил, что все новые инициативы, от внедрения ускорителей GB200 Grace Blackwell в Azure до новой интеграции между DGX Cloud и Microsoft Fabric, обеспечат клиентам наиболее полные платформы и инструменты на всех уровнях стека Copilot, от «кремния» до ПО, и позволят создать им новые прорывные ИИ-приложения. Microsoft станет одной из первых, кто развернёт в облаке ускорители GB200 и вкупе с InfiniBand-интерконнектом на базе Quantum-X800, предоставив новейшие базовые модели с триллионом параметров. Заодно компания объявила о доступности инстансов Azure NC H100 v5 на базе H100 NVL. Серия NC среднего уровня, предназначенная для обучения и инференса, предлагает клиентам два класса виртуальных машин с одним или двумя PCIe-ускорителями H100 (94 Гбайт). 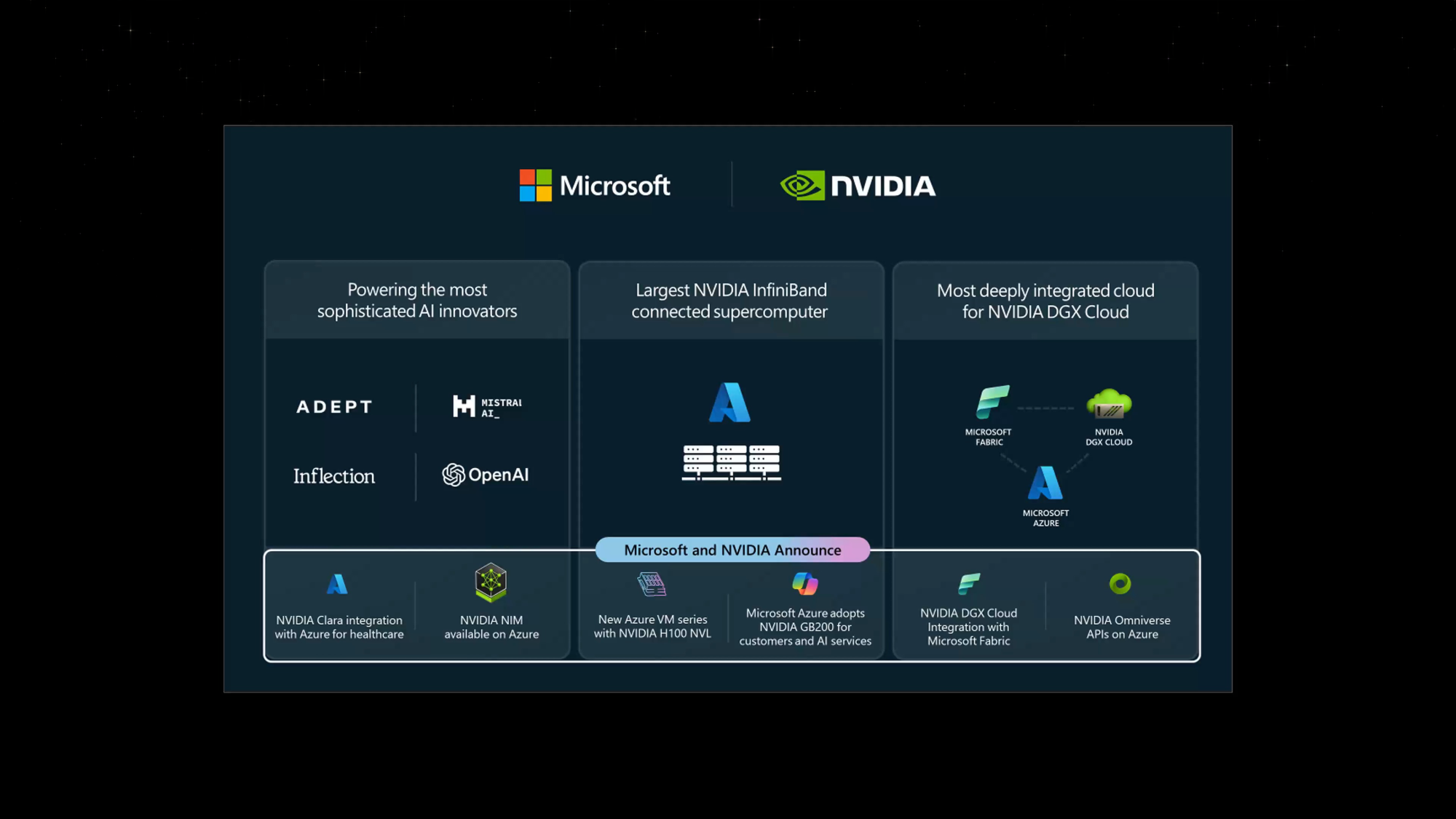
Изображение: NVIDIA Кроме того, компания предложит комплексный набор решений на базе Microsoft Azure, NVIDIA DGX Cloud и NVIDIA Clara поставщикам медицинских сервисов, фармацевтическим и биотехнологическим компаниям, а также разработчикам медицинского оборудования. А индустриальные компании получат в своё распоряжение API NVIDIA Omniverse Cloud. Наконеw, в Azure AI и Azure Marketplace станут доступны микросервисы инференса NVIDIA NIM.
19.03.2024 [22:37], Сергей Карасёв
HPE выпустила локальный суперкомпьютер для генеративного ИИКомпания HPE сообщила о доступности модульной суперкомпьютерной системы для генеративного ИИ. Платформа, предназначенная для локального размещения в инфраструктуре заказчика, построена на суперчипах NVIDIA GH200 Grace Hopper. О подготовке системы HPE заявила в ноябре 2023 года. В её основу положены серверы ProLiant DL380a Gen11. В общей сложности могут быть задействованы до 168 суперчипов GH200. Кроме того, применяются Ethernet-платформа NVIDIA Spectrum-X и DPU NVIDIA BlueField-3. Решение дополнено платформой машинного обучения и аналитическим программным обеспечением HPE, платформой для работы с ИИ-приложениями NVIDIA AI Enterprise 5.0, которая включает микросервисы на базе загружаемых программных контейнеров, а также сервисом NVIDIA NeMo Retriever и другими библиотеками для обработки данных и ИИ. Суперкомпьютерная система ориентирована на крупные предприятия, исследовательские институты и правительственные учреждения. 
Источник изображения: HPE Утверждается, что в конфигурации с 16 узлами комплекс может оптимизировать модель Llama 2 с 70 млрд параметров всего за 6 минут. Высокая производительность позволяет клиентам повысить продуктивность бизнеса с помощью приложений генеративного ИИ, таких как виртуальные помощники, умные чат-боты и средства корпоративного поиска. При этом софт HPE Machine Learning Inference позволит предприятиям быстро и безопасно развертывать масштабные модели машинного обучения. Компания HPE также сообщила о намерении выпустить продукты следующего поколения, использующие аппаратные решения NVIDIA на базе архитектуры Blackwell. Речь идёт о гибридных суперчипах GB200, а также изделиях HGX B200 и HGXB100. Подробности о новых системах будут раскрыты позднее. |
|